News


24 June 2024
Stowers Faculty EDGE Workshop prepares postdocs for the academic job market
The Faculty EDGE series is just one of many advantages of the postdoctoral training program at the Stowers Institute.
Read Article
News
Unsung molecular heroes link steps in gene expression, providing another hint to understanding biological complexity in humans


By Melissa Fryman
Consider the complexity of humans. We are capable of imagining scenarios, advanced planning, storytelling, and scheming. The stunning variation of humans, even among siblings, allows for a wide range of physical and character traits.
Our underlying biology is also complex. Perhaps the most surprising revelation from the Human Genome Project was that we have only around 22,000 genes that encode proteins. Although the number of different proteins comprising the human proteome—the collection of all proteins expressed by our genome—is still an unsettled issue, the number is estimated to be much higher than our number of genes. This raises the question: How do humans attain protein complexity without a corresponding number of genes?
Two recent studies led by Saikat Bhattacharya, PhD, a senior research associate in the laboratory of Jerry Workman, PhD, at the Stowers Institute for Medical Research, revealed a key link between two biological processes involved in creating proteome complexity out of information stored in the human genome.
These two fundamental biological phenomena—transcription and RNA splicing—play outsized roles in this context. Transcription creates RNA messages from genes. Before the messages are translated into proteins, they likely undergo splicing, which can create alternative versions of the messages. In this way, one gene can give rise to related but functionally different protein types, known as isoforms, depending on factors such as cell identity, tissue environment, or developmental stage. Remarkably, about 95% of human genes are estimated to undergo alternative splicing.
The two processes occur very close to each other in time and space, in the cell nucleus. While known to have crosstalk, they are usually studied independently of one another. In two papers published in Nature Communications, Bhattacharya and coauthors demonstrate a direct physical interaction between the transcription and alternative splicing machinery.
“Alternative splicing influences almost all fundamental processes in cells, so anything that changes this process can also result in disease,” explains Bhattacharya.
The creation or loss of a splice site in RNA can result in a non-functional or malfunctioning protein. One rare but striking example of this is seen in Hutchinson-Gilford progeria syndrome. Individuals with progeria have aberrant splicing of the LMNA gene, which leads to premature aging and drastically shortened life spans.
Just like film footage is spliced together during movie production and multiple people are involved in the editing process, depending on the target audience, so are multiple players involved in alternative splicing. One set of players is a family of molecules called heterogeneous ribonucleoproteins (hnRNPs). These RNA-binding proteins are widespread and are also involved in stabilizing RNA and regulating transcription.
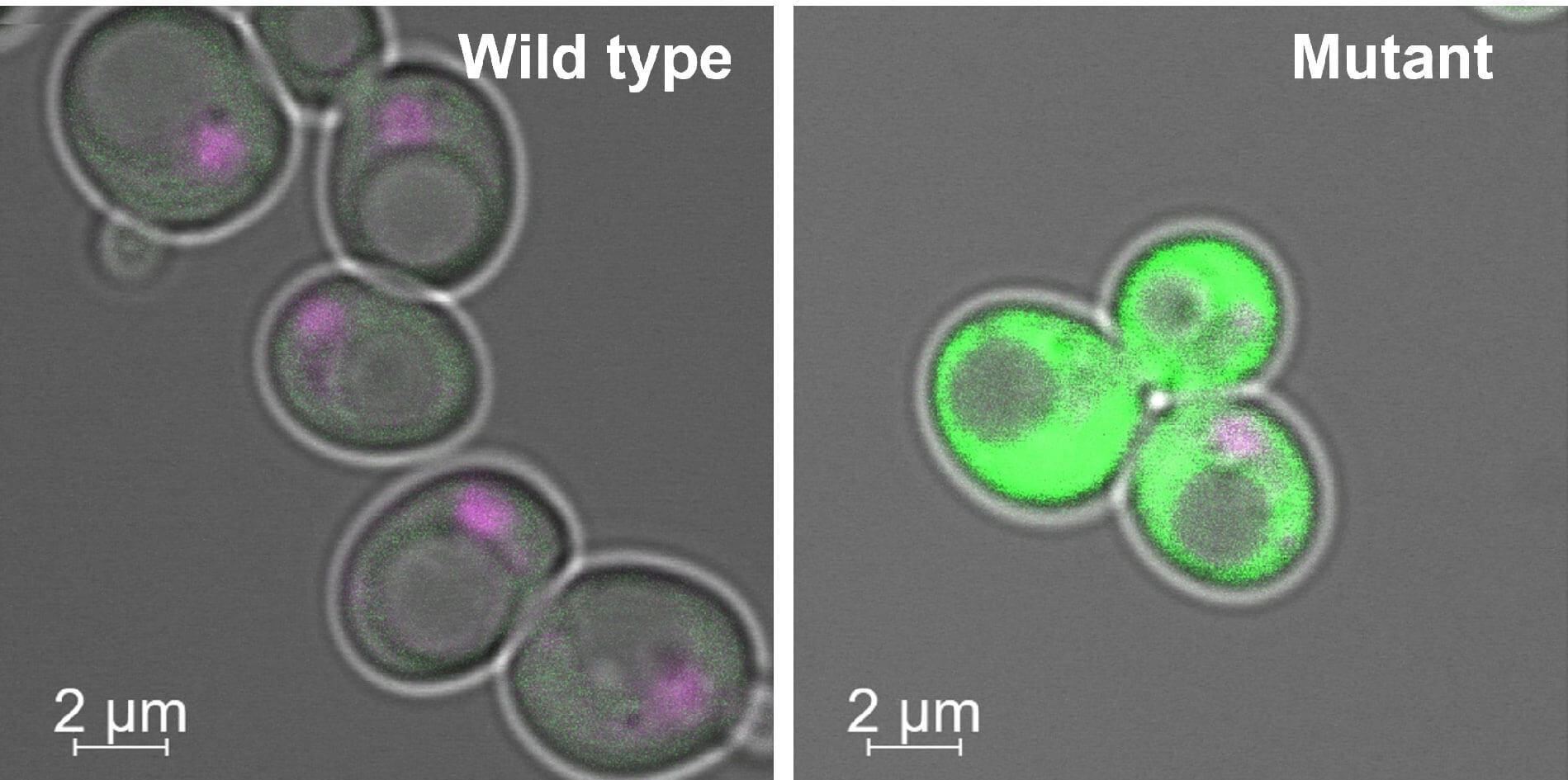
In their first paper, Bhattacharya and colleagues report that one of these molecules, hnRNP L, not only binds RNA, but also binds a protein called SETD2, which is known to be associated with the transcription machinery of cells. SETD2 is mutated in many cancers, especially in kidney carcinoma.
“A lot of SETD2 functions were believed to be the same as Set2—the yeast version of SETD2—based on their similarities and without direct experimentation,” explained Bhattacharya. “But when we took a closer look at SETD2 in human cells, we found it did not function exactly the same.” When the team followed up on this observation and biochemically purified SETD2 to determine its interacting proteins, they found a lot of hnRNPs also came with it.
“Researchers often ignore the hnRNPs in their purifications because they are known contaminants—they stick to RNA, so any traces of RNA in a sample will bring along these splicing regulatory proteins,” says Bhattacharya. “However, in our case, the hnRNPs were so abundant, it was difficult to ignore them.”
Was it possible that the researchers had identified a new function of SETD2—one that mediates the crosstalk between transcription and alternative splicing?
Bhattacharya and colleagues performed a series of experiments to test their hypothesis. First, they repeated their SETD2 protein purification, but this time adding an enzyme that degrades any RNA contaminants. They found that this step actually increased the levels of hnRNPs in their purifications. “This was the key experiment that showed that SETD2-hnRNP binding might indeed be real and not just proteins sticking because of RNA,” said Battacharya.
Encouraged by these findings, they performed biochemical experiments to identify a relatively small, 50-amino-acid region in SETD2 that could bind to the hnRNPs. Next, they deleted this region of SETD2 to test whether hnRNP co-purification was affected. Indeed, this mutation drastically reduced the presence of hnRNPs by Western blotting, a classical method of detecting proteins. Still not completely satisfied, Bhattacharya and colleagues then confirmed their results with mass spectrometry, a more sensitive protein-detection technology. Again, no hnRNPs were detected with SETD2 lacking the 50-amino-acid region.
“This was the eureka moment for us. We knew we had discovered a novel domain in SETD2,” says Bhattacharya. The researchers landed on naming it the SHI domain, which stands for the SETD2-hnRNP Interaction domain. SHI also happens to bear a phonetic similarity to the first syllable of Saikat in Bengali, Bhattacharya’s native language.
Bhattacharya and colleagues teamed up with talented protein crystallization researchers from the University of Science and Technology of China in Hefei, Anhui, to determine the structural basis of the interaction. Described in a second paper, this work revealed the specific amino acids that mediate the SETD2-hnRNP L interaction. Importantly, this is one of the very few studies that show how RNA-binding hnRNPs engage with a protein.


Saikat Bhattacharya, PhD
The SHI domain is conserved in SETD2 across vertebrates, while other amino acid residues of SETD2 are not. Consistent with the fact that alternative splicing in yeast is rare, the SHI domain does not exist in Set2. This newly identified domain can now be studied for its relevance in the context of cancers, and as a target for small-molecule treatments to promote or inhibit alternative splicing.
“It seems as if SETD2 gained a domain in more complex organisms so it could expand its function to include alternative splicing,’” says Bhattacharya. “But it’s not just about SETD2 and hnRNPs—these are just one pair of molecules demonstrating that this kind of relationship exists in the cell. Our finding shows that there are protein molecules like SETD2 that can be at the interface of the coupling of transcription and alternative splicing. It’s likely that there are more such proteins that are yet to be discovered. Such discoveries will be crucial for a better understanding of alternative splicing and the diseases where this process goes wrong.”
Additional contributors to the studies were Michaella J Levy, Ning Zhang, PhD, Hua Li, PhD, Laurence Florens, PhD, Divya Reddy, PhD, and Ying Zhang, PhD, from the Stowers Institute; Michael P. Washburn, PhD, from the University of Kansas Medical Center; and Suman Wang, Siyuan Shen, Yunyu Shi, and Fudong Li from the University of Science and Technology of China, Hefei, Anhui.
News
24 June 2024
The Faculty EDGE series is just one of many advantages of the postdoctoral training program at the Stowers Institute.
Read Article
News


17 January 2024
Q&A with Stowers Postdoc Michael Church: “When I got the opportunity to join the Workman Lab, I jumped at the chance.”
Read Article
News


06 October 2023
Forty-nine members reached 20 years of service at the Stowers Institute. The Institute founders, Jim and Virginia Stowers, envisioned establishing the Institute as a long-term investment for advancing foundational knowledge in biology for the benefit of all.
Read Article